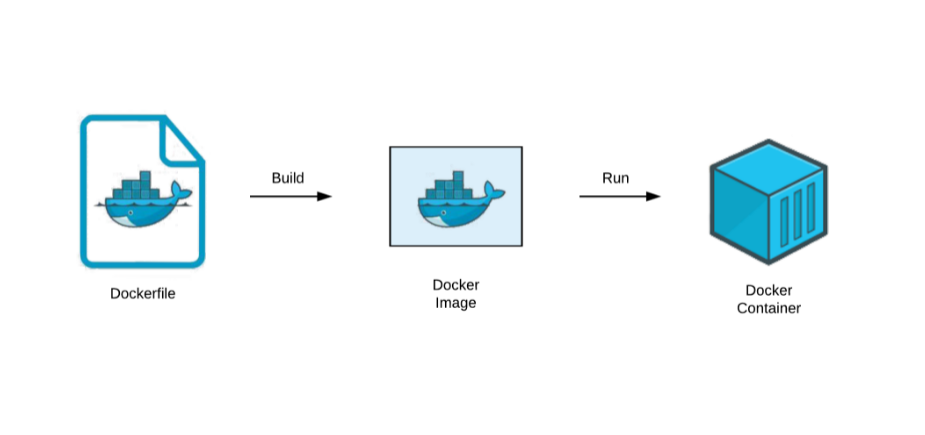
Introduction to Docker Swarm
Docker Swarm is Docker’s native clustering and orchestration solution that lets you manage multiple Docker containers across different machines. Think of it like a conductor orchestrating a symphony – but instead of musicians, you’re coordinating containers. If you’re new to containerization, a container is like a lightweight, standalone package that includes everything needed to run a piece of software.
Understanding Docker Swarm Fundamentals
What is Docker Swarm?
Imagine you have a fleet of delivery trucks (containers) that need to deliver packages (applications). Docker Swarm is like having a central dispatch system that coordinates all these trucks, ensuring they work together efficiently. It takes multiple individual Docker hosts (computers running Docker) and combines them into a single, unified system that’s easier to manage.
Learn: How to Install Docker on Ubuntu: A Step-by-Step Guide
Key Features Explained
- Built-in Orchestration: Like a traffic control system, it automatically directs containers to the right machines
- Declarative Service Model: You tell it what you want (like “I need 5 copies of this application running”), and it makes it happen
- Scaling: Need more power? It’s like adding more delivery trucks to your fleet with a simple command
- Load Balancing: Automatically distributes work evenly, like having a smart dispatcher ensuring no single truck gets overloaded
- Service Discovery: Containers can find each other automatically, like trucks knowing exactly where to pick up and deliver
- Rolling Updates: Update your applications without downtime, like replacing trucks one at a time while deliveries continue
- Self-Healing: If a container fails, Swarm automatically replaces it, like having a backup truck ready to go
Architecture and Components
Node Types in Detail
1. Manager Nodes
Think of manager nodes as the supervisors in a warehouse:
- Control Plane: Like the warehouse control room where all decisions are made
- State Management: Keeps track of everything happening in the swarm, like a detailed inventory system
- API Endpoints: Provides interfaces for giving commands, like the supervisor’s communication system
- Raft Consensus: Uses a voting system to maintain consistency (at least 51% of managers must agree on decisions)
Best Practice: For reliability, use:
- 3 managers for small to medium swarms (can handle 1 manager failure)
- 5 managers for large swarms (can handle 2 manager failures)
- Never use 2 or 4 managers (can cause split-brain issues)
2. Worker Nodes
Like the actual warehouse workers:
- Task Execution: Run the actual containers, like workers handling packages
- Status Reporting: Regularly updates managers about their work progress
- Resource Provision: Provides CPU, memory, and storage for containers
Core Components Explained
1. Control Plane
Like the brain of the operation:
- Purpose: Makes all high-level decisions
- Functions:
- Maintains cluster state
- Handles manager-to-manager communication
- Processes API requests
- Makes global scheduling decisions
2. Orchestrator
Like a project manager:
- Role: Ensures the actual state matches what you asked for
- Example: If you want 5 containers running, it makes sure exactly 5 are running
- Actions:
- Creates new tasks if containers fail
- Scales services up or down
- Maintains desired state
3. Allocator
Like an address assigner:
- Purpose: Manages IP addresses for containers
- Functions:
- Assigns unique IP addresses to services
- Ensures no IP conflicts
- Manages network aliases
4. Dispatcher
Like a task distributor:
- Role: Assigns tasks to specific nodes
- Considerations:
- Node availability
- Resource constraints
- Placement preferences
5. Scheduler
Like a resource planner:
- Purpose: Decides which specific node runs each container
- Factors Considered:
- Resource availability (CPU, memory)
- Node constraints
- Placement strategies
Service Configuration Options Explained
1. Replicas
Like copies of your application:
# Create a service with 3 replicas docker service create --name webserver --replicas 3 nginx
- Definition: Number of identical containers running your application
- Purpose: Provides redundancy and scalability
- Example: Running 3 copies means your service stays up even if 1 or 2 fail
2. Placement Constraints
Like rules for where containers can run:
# Run only on nodes with SSD storage docker service create --constraint 'node.labels.storage==ssd' nginx
- Definition: Rules that determine which nodes can run your containers
- Types:
- Node labels
- Node roles
- Engine labels
- Custom constraints
3. Resource Limits
Like setting boundaries for resource usage:
# Limit CPU and memory usage docker service create --reserve-cpu 0.5 --reserve-memory 512M nginx
- CPU Limits: How much processing power a container can use
- Memory Limits: Maximum RAM allocation
- Storage Limits: Disk space restrictions
4. Update Configuration
Like rules for updating your application:
# Configure gradual update docker service update \ --update-parallelism 2 \ --update-delay 20s \ --update-failure-action rollback \ myservice
- Parallelism: How many containers to update at once
- Delay: Wait time between updates
- Failure Action: What to do if update fails
Networking in Docker Swarm Explained
1. Overlay Networks
Like a virtual network connecting all your containers:
# Create an overlay network docker network create --driver overlay mynetwork
- Purpose: Allows containers on different hosts to communicate
- Features:
- Encrypted communication option
- Service discovery
- Load balancing
2. Ingress Network
Like a front door to your services:
- Purpose: Routes external traffic to the right containers
- Features:
- Automatic load balancing
- Public-facing service access
- Port mapping
Stack Deployment Explained
A stack is like a complete application blueprint:
# Detailed docker-stack.yml example
version: '3.8'
services:
webapp:
image: nginx:latest
deploy:
# How many copies you want
replicas: 3
# Rules for updates
update_config:
parallelism: 1 # Update one container at a time
delay: 10s # Wait 10 seconds between updates
order: start-first # Start new container before stopping old
# What to do if container fails
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
# Resource limits
resources:
limits:
cpus: '0.5'
memory: 512M
# Network settings
networks:
- frontend
- backend
networks:
frontend:
driver: overlay
backend:
driver: overlay
internal: true # Only internal accessEach section defines a specific aspect of your application:
- Services: The containers that make up your application
- Networks: How containers communicate
- Volumes: Where data is stored
- Secrets: Sensitive information management
- Configs: Configuration management
Rolling Updates Explained
Like updating cars on a moving assembly line:
Components of a Rolling Update
- Parallelism: Number of simultaneous updates
--update-parallelism 2 # Update 2 containers at once
- Delay: Time between updates
--update-delay 20s # Wait 20 seconds between updates
- Failure Action: What to do if something goes wrong
--update-failure-action rollback # Go back to previous version
- Update Order: How to sequence the updates
--update-order start-first # Start new before stopping old
Process Explained:
- New container is deployed
- Health check runs
- If healthy, old container is removed
- Process repeats for each container
- If failure occurs, rollback begins
This careful, step-by-step process ensures your application stays available during updates.
Monitoring and Troubleshooting
Monitoring Commands Explained
# View detailed service logs with timestamp docker service logs --timestamps --follow myservice # Get detailed service information docker service inspect --pretty myservice # Check specific task status docker service ps --filter "desired-state=running" myservice
Each command provides specific insights:
- logs: Shows container output (like reading a ship’s log)
- inspect: Reveals service configuration (like checking blueprints)
- ps: Shows task status (like checking worker status)
Health Check Implementation
healthcheck: test: ["CMD", "curl", "-f", "http://localhost"] interval: 30s timeout: 10s retries: 3 start_period: 40s
Explanation of each parameter:
- test: The command to check health
- interval: How often to check
- timeout: How long to wait for response
- retries: Number of failures allowed
- start_period: Initial grace period
Best Practices and Production Tips
1. High Availability Setup
Like having backup systems:
- Manager Distribution: Place managers in different data centers
- Backup Strategy: Regular state backups
- Recovery Plan: Documented recovery procedures
2. Security Guidelines
Like setting up a security system:
- Network Segmentation: Separate different types of traffic
- Secret Management: Secure handling of sensitive data
- Access Control: Strict permission management
3. Performance Optimization
Like tuning an engine:
- Resource Allocation: Proper CPU and memory limits
- Network Configuration: Optimized network settings
- Monitoring Setup: Comprehensive monitoring system
Top 50 Docker Commands for Daily Use
Production Readiness Checklist
Detailed steps to ensure production readiness:
1. Infrastructure Requirements
- [ ] Sufficient hardware resources allocated
- [ ] Network configuration validated
- [ ] Storage requirements met
2. Security Measures
- [ ] TLS certificates configured
- [ ] Secrets management implemented
- [ ] Network policies defined
3. Monitoring and Logging
- [ ] Monitoring tools configured
- [ ] Log aggregation set up
- [ ] Alert system implemented
4. Backup and Recovery
- [ ] Backup strategy documented
- [ ] Recovery procedures tested
- [ ] Disaster recovery plan created
Conclusion
Docker Swarm provides a robust platform for container orchestration, suitable for both small applications and large-scale deployments. By understanding these components and following best practices, you can build reliable, scalable, and maintainable containerized applications.
Remember: Start small, test thoroughly, and scale gradually. Your swarm can grow as your needs grow.

Whether you’re looking for troubleshooting tips, deep dives into systems architecture, or the latest in cloud computing, At Yourcomputer.in, I’m here to help you navigate the evolving tech landscape. Let’s connect, learn, and grow together!
📧 ravi.chopra1709@gmail.com
- Why should you automate Active Directory cleanup? - 17 June 2025
- Troubleshooting: Unable to Add Instance Failover Group to Azure SQL Managed Instance - 4 March 2025
- 10 Azure Virtual Desktop (AVD) Cost-Optimization Strategies for 2025 💡💰 - 22 February 2025